TLDR: Splatting features enable precise and efficient grasping in dynamic environments
Abstract
The ability for robots to perform efficient and zero-shot grasping of object parts is crucial for practical applications and is becoming prevalent with recent advances in Vision-Language Models (VLMs). To bridge the 2D-to-3D gap for representations to support such a capability, existing methods rely on neural fields (NeRFs) via differentiable rendering or point-based projection methods. However, we demonstrate that NeRFs are inappropriate for scene changes due to its implicitness and point-based methods are inaccurate for part localization without rendering-based optimization. To amend these issues, we propose GraspSplats. Using depth supervision and a novel reference feature computation method, GraspSplats generates high-quality scene representations in under 60 seconds. We further validate the advantages of Gaussian-based representation by showing that the explicit and optimized geometry in GraspSplats is sufficient to natively support (1) real-time grasp sampling and (2) dynamic and articulated object manipulation with point trackers. With extensive experiments on a Franka robot, we demonstrate that GraspSplats significantly outperforms existing methods under diverse task settings. In particular, GraspSplats outperforms NeRF-based methods like F3RM and LERF-TOGO, and 2D detection methods.
Constructing Feature-enhanced 3D Gaussians
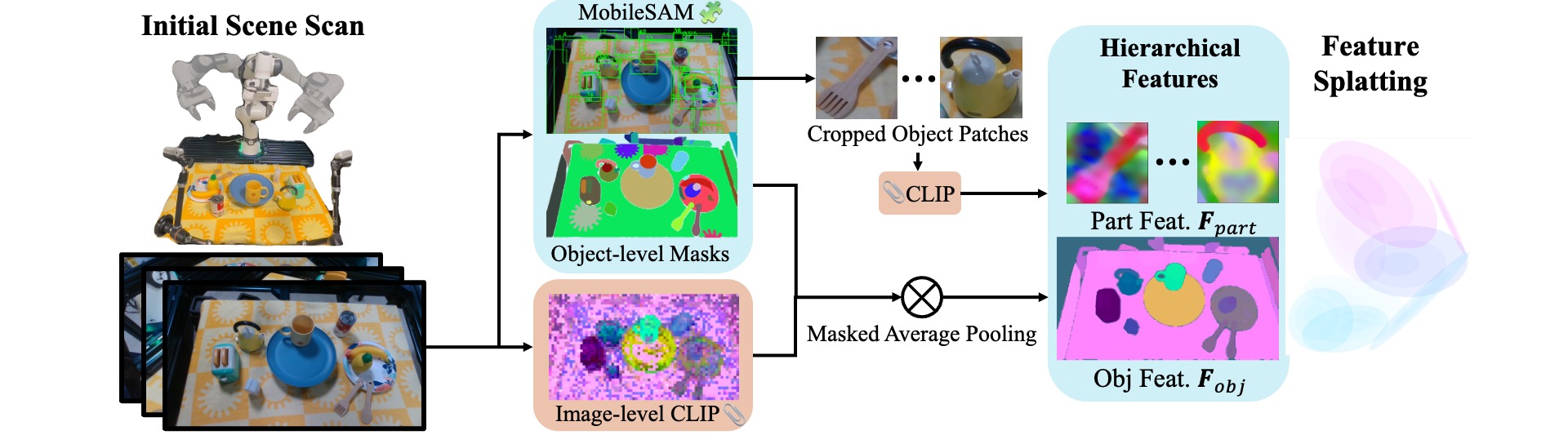
GraspSplats employs two techniques to efficiently construct feature-enhanced 3D Gaussians: hierarchical feature extraction and dense initialization from geometry regularization, which reduces the overall runtime to 1/10 of existing GS methods.
Qualitative Open-vocabulary Segmentation Results
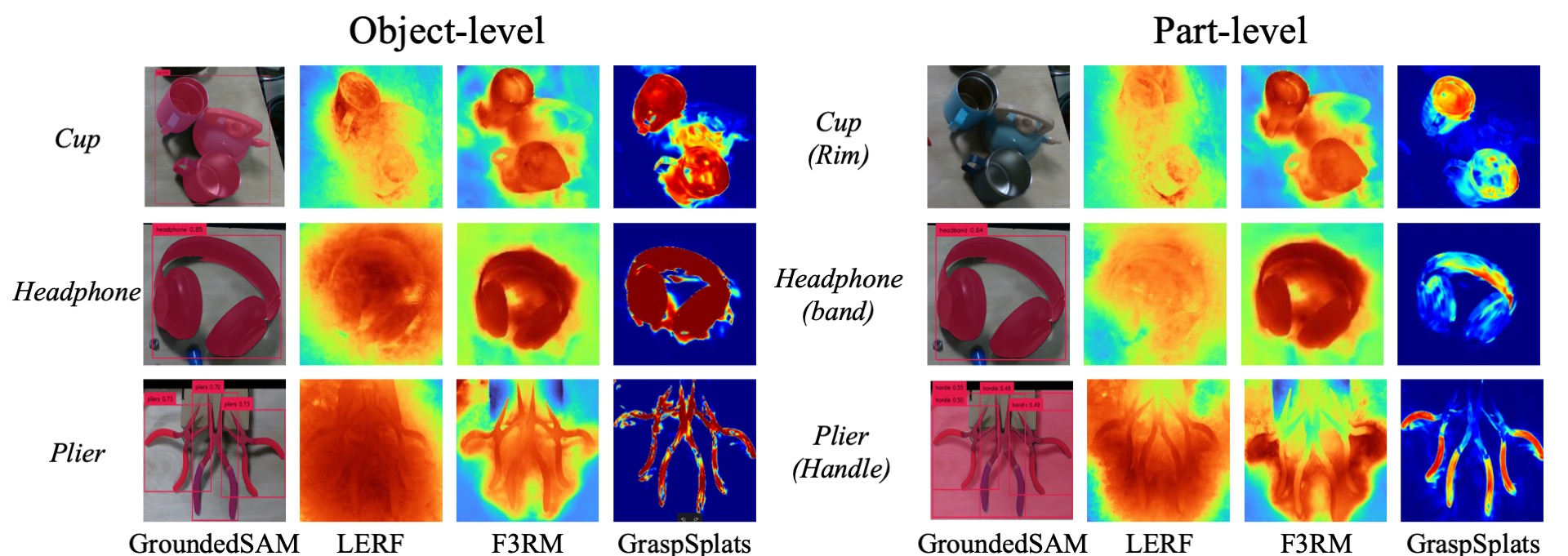
Precise Part Level Grasping in Staic Scenes
Pick up the cup by the rim.
Pick up the charger by the plug.
Pick up the gray teapot by the handle.
Pick up the headphones by the headband.
Pick up the screwdriver by the handle.
Open the white door by the gray handle.
Move the apple to the sink.
Open the drawer by the green handle.
Rapid Sequential Query and Grasping of Objects
Fast grasp all the toys on the table.
Fast grasp the screwdrivers on the table.
Grasping Pipeline in Dynamic Scenes
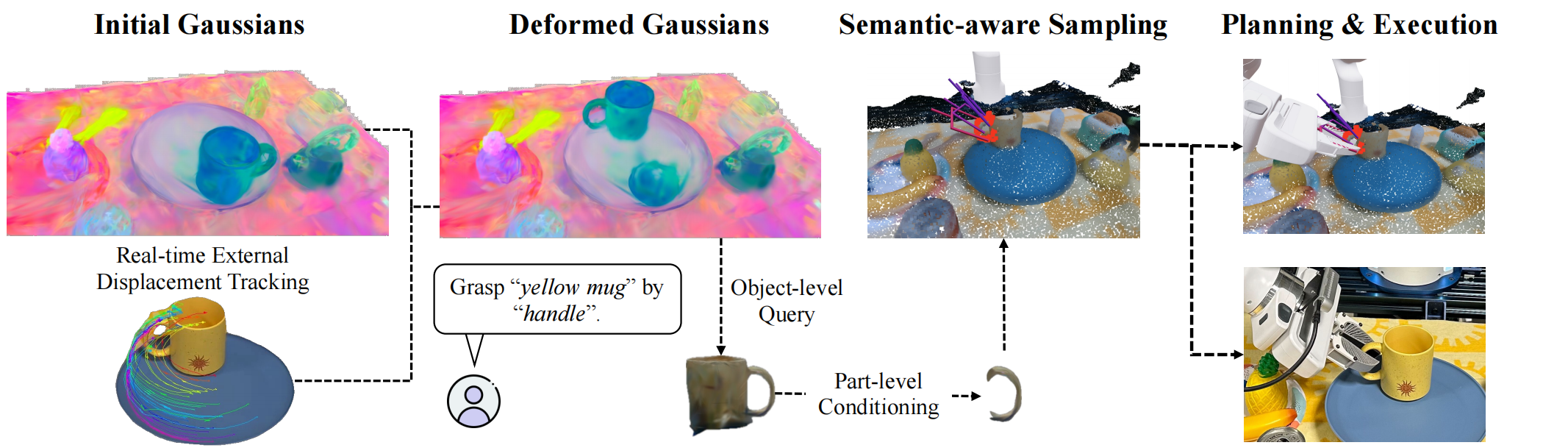
Given an initial state of Gaussians and RGB-D observations from one or more cameras, GraspSplats tracks the 3D motion of objects specified via language, which is used to deform the Gaussian representations in real-time. Given object-part text pairs, GraspSplats proposes grasping poses using both semantics and geometry of Gaussian primitives in milliseconds.
Grasping Applications in Dynamic Environments
After the white door is open, close it using the gray handle.
Follow the gray teapot and lift it by handle once it stops.
Put the pineapple in the purple bowl when the turntable stops.
After the yellow ball is hit, place it back in its original position.
Return the toy car to the starting point if it gets stuck.
Once the white cup is placed down, lift it up by the rim.
Track all the dolls and grasp them once they have stopped.
Overview (long version)
Bibtex
@article{ji2024-graspsplats,
title={GraspSplats: Efficient Manipulation with 3D Feature Splatting},
author={Mazeyu Ji and Ri-Zhao Qiu and Xueyan Zou and Xiaolong Wang},
journal={arXiv preprint arXiv:2409.02084},
year={2024}
}